OceanProtect 1.3.0 Backup Storage Solution Best Practice (Integration with SAP HANA)

1 About This Document
Purpose
This document describes the best practices for backing up and restoring data based on OceanProtect backup storage and in-memory computing platform SAP HANA.
Intended Audience
This document is intended for:
- Marketing engineers
- Technical support engineers
Symbol Conventions
Symbols that may be found in this document are defined as follows.
Symbol | Description |
|---|---|
 | Indicates a hazard with a high level of risk which, if not avoided, will result in death or serious injury. |
 | Indicates a hazard with a medium level of risk which, if not avoided, could result in death or serious injury. |
 | Indicates a hazard with a low level of risk which, if not avoided, could result in minor or moderate injury. |
 | Indicates a potentially hazardous situation which, if not avoided, could result in equipment damage, data loss, performance deterioration, or unanticipated results. NOTICE is used to address practices not related to personal injury. |
 | Supplements the important information in the main text. NOTE is used to address information not related to personal injury, equipment damage, and environment deterioration. |
Change History
Issue | Date | Description |
|---|---|---|
01 | 2023-08-01 | This issue is the first official release. |
2 Solution Overview
The backup storage solution provides a backup system with software and hardware deployed independently. It includes the backup software, backup agent, backup management servers, backup storage servers, and backup storage. Figure 2-1 shows the solution architecture.
Figure 2-1 Backup storage solution architecture
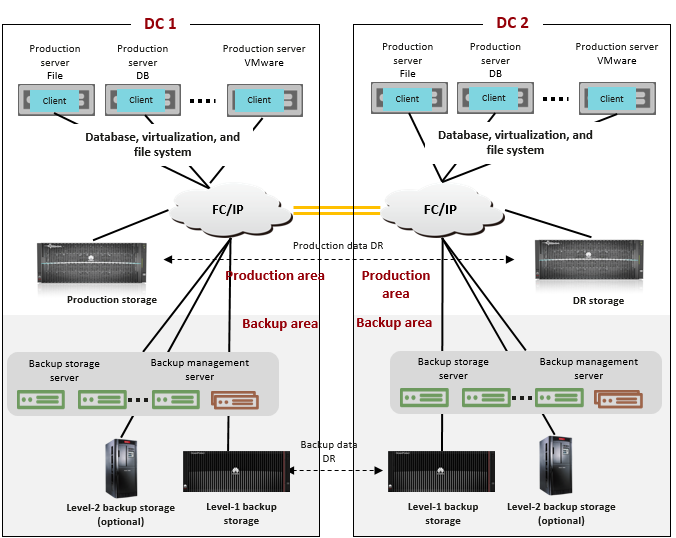
Components
- Mainstream backup software includes Veritas NetBackup, Veeam, Commvault, and more.
- The backup management servers manage components in the backup system and are used to create, execute and schedule backup jobs and configure backup policies. The backup management servers can be deployed independently or together with media servers.
- Installed on protected application production servers and VMs, the backup agent client responds to backup job scheduling of the backup management servers, collects and manages data to be protected, and transmits the data to the backup storage servers.
- The backup storage servers (also called media servers) are independently deployed and respond to job scheduling of the backup management servers. The backup storage servers process backup data flows and manage backup data transmission and storage devices of backup data. Some vendors also provide backup data deduplication and compression capabilities on backup storage servers.
- Backup storage, which is connected to the backup storage servers, is used to receive and store backup data. Some backup storage devices also provide deduplication and compression capabilities. Based on service requirements, backup storage can be designed as two levels. Level-1 backup storage provides fast and efficient backup and data restoration capabilities, delivering optimal backup and restoration performance. The cost of level-1 backup storage is high, and data deduplication and compression are important. Level-2 backup storage stores data for a long term at a low cost. Backup copies stored for more than a certain period of time are migrated to level-2 backup storage, achieving the optimal comprehensive retention cost. Common backup storage types include backup storage, general-purpose storage, virtual tape libraries (VTL), object storage, and tape libraries.
Solution Description
- During backup, the backup management server delivers a backup scheduling command to the backup agent so that the backup agent collects and transmits data based on the specified backup policy. The backup storage server processes the data transmitted by the backup agent, writes the data to the backup storage in a certain format, and records the index.
- Due to the performance upper limit of a single backup storage server, if the processing performance is insufficient, scale-out of backup storage servers is supported.
- Backup data replication: Based on compliance and data security requirements, remote disaster recovery (DR) is also required for backup data. Data can be replicated and transmitted through the backup storage server or level-1 backup device.
- Long time retention (LTR) of backup data: The LTR solution is a suitable choice if customers want to retain backup copies for a long time and require quick recovery. According to policies, the most recent copies are stored on level-1 backup media to provide quick backup, quick access, and recovery capabilities. Copies that need to be stored for a long time are stored on level-2 backup media with lower cost to achieve long-term storage at a low cost. The combination of the two types of storage media helps achieve the optimal comprehensive retention cost.
This document describes the backup storage solution based on OceanProtect backup storage integrating SAP HANA backup software.
3 Solution Introduction
Based on the in-memory computing platform SAP HANA and Huawei OceanProtect backup storage, the backup storage solution is formed to back up and restore data.
3.1 Solution Components
3.1.1 SAP HANA
SAP HANA is short for SAP High-performance ANalytic Appliance. SAP HANA is a brand-new and innovative in-memory database platform that effectively solves the problem of analyzing big data in near real time. HANA makes full use of brand-new hardware technologies, such as column-oriented storage, modern CPU, and in-memory computing technologies, to realize massive parallel processing. As a result, HANA’s real-time analysis space can support a large number of application cases. In addition, SAP HANA can be deployed as the underlying database for SAP Business Suite applications.
As a system combining hardware with software, the SAP HANA system provides high-performance data query and allows users to directly query and analyze massive sets of real-time service data without modeling and aggregating service data.
Each node of HANA is an x86 server with CPU, memory, and disks as the node’s hardware, and the operating system and HANA application system as the node’s software. HANA uses multi-CPU parallel processing and in-memory database technologies. Data in the SAP HANA in-memory database is not only stored in the memory, but also written to disks continuously. HANA runs Linux operating systems, including SUSE Linux Enterprise Server (SLES) and Red Hat Linux. Hardware vendors mainly include Huawei, Dell, HP, IBM, Cisco, Fujitsu, and NEC.
SAP HANA Architecture
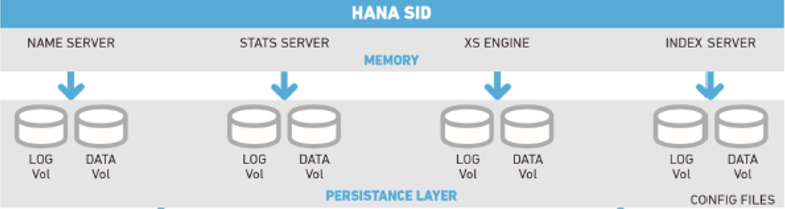
Each HANA database possesses a unique SID. The HANA system can be single-node or multi-node. A multi-node system supports parallel processing and HA configuration to realize failover. Each HANA node provides up to four services:
- Name Server
- Statistics Server
- XS Engine
- Index Server
Each of the four servers has its own data volumes and log volumes. In single-node configuration, if workloads need to be increased, add more memory and CPUs to the local node to enhance the HANA database processing capability. The following figure shows the single-node configuration.
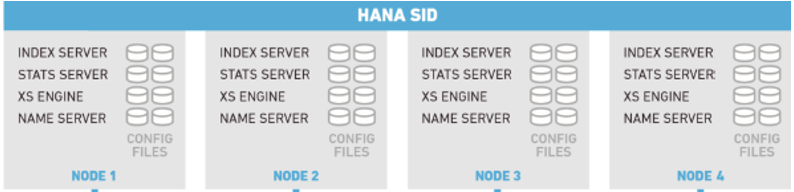
SAP HANA supports the horizontal scaling option as well. One database can be distributed to multiple nodes through adding more nodes, greatly increasing the data processing capabilities. A production system can be configured with only one SID (single database) while a non-production system can be configured with multiple SIDs (multiple databases). The following figure shows the multi-node configuration.
Importance of Backup for SAP HANA
The HANA system stores data in memory to ensure best performance of the system. However, to prevent data loss caused by memory faults such as power failure, SAP HANA also adopts persistent storage systems to save data, which allows the HANA system to be restored in the event of memory faults. In normal database operations, a Savepoint operation is performed periodically. Data and undo logs are automatically written to hard disks during the Savepoint process, and data changes are recorded in redo logs. The logs can also be written to hard disks if certain conditions are met. Write operations of Savepoint and redo logs can prevent any memory fault from affecting the database. However, when a fault occurs in persistent storage devices (such as a disk), the HANA system cannot be restored. To prevent data loss caused by hardware faults, it is necessary to back up data on persistent storage devices. The impact incurred by the backup operation process on the SAP HANA performance is slight and can be ignored. The system can keep working normally.
Methods of Protecting SAP HANA
Three methods of protecting SAP HANA:
- File-level backup: writes backup data to the file system of the local storage system.
- Backup based on storage-level snapshots: protects data volumes.
- Backup based on the Backint backup interface (a streaming backup interface defined by SAP): integrates third-party backup software.
In this solution, SAP HANA data is directly backed up to OceanProtect backup storage. That is, the file-level backup method is used.
3.1.2 OceanProtect Backup Storage
Service Positioning
As the amount, types, and growth rate of data change exponentially, enterprises face increasing data loss risks due to unintentional deletion, viruses, natural disasters, and other network security threats. Therefore, data protection becomes increasingly important.
OceanProtect backup storage features rapid backup and rapid recovery, efficient reduction, and solid resilience, and helps to implement efficient backup and restoration and greatly reduce the TCO. It is widely used in government, financial, carrier, healthcare, and manufacturing industries. In addition, it offers easy-to-use management modes and convenient local/remote maintenance modes, significantly decreasing the management and maintenance costs.
OceanProtect backup storage is available in SSD form and HDD form.
- SSD form: The system supports only solid-state drives (SSDs). Both service data and metadata are stored in SSDs.
- HDD form: The system supports both SSDs and hard disk drives (HDDs). Service data is stored in the storage pool composed of HDDs. SSDs only store system metadata. SSDs with superb performance can accelerate access to metadata, improving read/write performance.
Product Highlights
Based on the full-process acceleration and active-active high-reliability architecture, OceanProtect backup storage features rapid backup and rapid recovery, efficient reduction, and solid resilience.
In addition, OceanProtect 1.2.0 provides new features such as source deduplication and deduplicated replication to effectively increase the logical bandwidth and decrease the network resource occupation for customers.
- Rapid backup, rapid recovery
- Full-process acceleration is implemented. The front-end network protocol offload technology reduces the CPU pressure, and the back-end CPU multi-core parallel scheduling is implemented. Dedicated cores are used through grouping and task partitioning, efficiently improving the processing capability of nodes.
- Multiple sequential data flows are aggregated for read and write to greatly improve bandwidth performance. Source deduplication reduces the amount of data to be transmitted over the network and shortens the backup duration.
- The system provides high IOPS performance and can work with mainstream backup software. Backup image data can be accessed immediately, implementing fast utilization of backup data.
- Efficient reduction
- Accurate backup data segmentation, backup data aggregation preprocessing, and multi-layer inline variable-length deduplication are used to increase the logical capacity and reduce the total cost of operations (TCO).
- Data flow features can be identified. Compression after combination, high-performance predictive encoding, and byte-level compaction are used to improve the data reduction ratio.
- Source deduplication and replication link deduplication save network bandwidth costs.
- Solid resilience
- The active-active hardware architecture design ensures that ongoing backup tasks can be switched over within seconds if a single controller is faulty, ensuring uninterrupted backup tasks.
- Protocol encryption, replication link encryption, array encryption, secure snapshots, and write once read many (WORM) are used to ensure security and availability of copies.
3.2 Solution Architecture
3.2.1 Overall Solution Architecture
Figure 3-1 Architecture of the solution for directly backing up SAP HANA applications to the backup storage
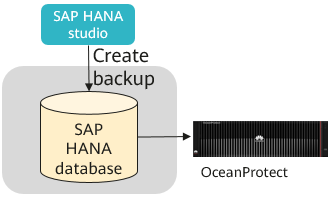
Solution overview
OceanProtect mounts NAS file systems to SAP HANA servers through DataTurbo or NFS and backs up and restores data by using the built-in backup tool on the SAP HANA software interface.
Application scenarios
- The customer only needs to back up a single SAP HANA application.
- The customer does not need enterprise-level backup software construction.
- There are no advanced requirements, such as geographic redundancy and tiered archiving of backup copies.
Solution features
- The configuration and O&M are simple. Backup can be performed by using just one NAS share.
- OceanProtect provides both DataTurbo source deduplication and source deduplication on the SAP HANA application side. Only deduplicated backup data is transmitted.
- There are no scheduled backup job mechanisms of enterprise-level backup software, or copy retention period mechanisms. Expired copies need to be manually backed up and deleted.
4 Planning Suggestions
4.1 Network Planning for Different OceanProtect Models
In OceanProtect 1.3.0, the customer can select OceanProtect X3000, X6000, X8000, and X9000 based on different backup capacity and performance requirements. The networking configuration principles of all models must comply with the principles described in 5.3 Configuration Planning for Integrating SAP HANA.
4.2 Backup Planning for Integrating Applications
This solution involves no backup software and only integrates SAP HANA, a production application. For details about the integration planning, see 5.3 Configuration Planning for Integrating SAP HANA.
4.3 Planing for System Backup Capacity and Performance
- Backup capacity calculation
The OceanProtect capacity is planned based on the customer’s backup data capacity and copy retention policy.
- Backup performance calculation
The backup performance of the backup system is planned based on the customer’s backup window, backup copy capacity, and OceanProtect configuration. In this best practice, the planned backup bandwidth of a single SAP HANA server is 2 GB/s.
5.1 Configuration Example
In this chapter, OceanProtect X8000 (with source deduplication provided) integrates the SAP HANA server. Backup, restoration, and remote replication configuration processes as well as test results are provided.
5.2 Solution Networking
Figure 5-1 shows an example of the networking diagram of this best practice.
Figure 5-1 Networking diagram of backup using OceanProtect X8000 and SAP HANA
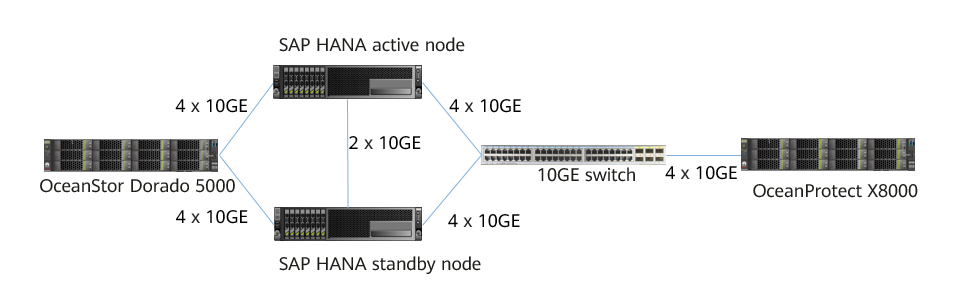
Figure 5-1 is only an example. For details about connections between OceanProtect X8000 controller enclosures and application servers, between controller enclosures and disk enclosures, and between controller enclosures, see « Cabinet Layout and Connection Planning » in the OceanProtect X6000, X8000 1.x Installation Guide.
The networking is described as follows:
- SAP HANA: Deploy two physical hosts to form an active/standby node cluster and connect it to an external production storage device.
- Two SAP HANA hosts use OceanStor Dorado 5000 as the production storage. Directly connect each SAP HANA host to the storage by using 4 x 10GE iSCSI links. Set up replication links between two SAP HANA hosts by using 2 x 10GE links. The two hosts form an active/standby node cluster.
- OceanStor Dorado 5000 uses 8 x 10GE links (4 x 10GE links for each controller). Create LUNs on OceanStor Dorado 5000 and mount them to SAP HANA hosts using the iSCSI protocol as data file storage volumes.
- Each SAP HANA host uses 2 x 10GE optical fibers to connect to OceanProtect X8000 through a 10GE switch.
- OceanProtect X8000: Connects to the 10GE switch through 4 x 10GE optical fibers. Each controller connects to 2 x 10GE optical fibers. Four physical ports are backup links connected to backup servers.
5.2 Hardware and Software Configuration
5.2.1 Hardware Configuration
Name | Description | Quantity | Function |
|---|---|---|---|
SAP HANA server | x86 server CPU: 2 x Intel(R) Corporation Montage Jintide(R) C5218R Memory: 256 GB Network: 8 x 10GE optical ports | 2 | Active/standby SAP HANA nodes installed with SAP HANA 2.0 |
Production storage | Huawei OceanStor Dorado 5000 with dual controllers, 25 SSDs (3.84 TB each), and two 4-port 10 Gbit/s SmartIO interface modules | 1 | Production storage that stores production service data to be backed up and tested |
Backup service switch | Huawei CE6850 | 2 | 10GE switch on the backup service plane |
5.2.2 OceanProtect X8000 (All-Flash) Configuration
Table 5-1 OceanProtect X8000 (all-flash) configuration
Name | Description | Quantity |
|---|---|---|
OceanProtect engine | Huawei OceanProtect X8000 with dual controllers | 2 |
10GE front-end interface module | 4 x 10 Gbit/s SmartIO interface modules | 2 |
SAS SSD | Huawei 7.68 TB SAS SSD | 25 |
5.2.3 Test Software and Tools
Table 5-2 Software description
Software Name | Description |
|---|---|
OceanStor DataTurbo 1.1.0 | The SourceDedupe client software. It is deployed on the backup server for source deduplication and compression on backup data to reduce the amount of physical data transmitted from the backup server to storage and improve the overall bandwidth of backup services. |
SAP HANA 2.0 | SAP HANA In-Memory Computing Platform |
SUSE12 SP4 | SUSE Linux Operating System |
SSH client software | SSH terminal connection tool |
5.3 Configuration Planning for Integrating SAP HANA
- Storage pool on OceanProtect X8000: Create a storage pool, configure 10 x SAS SSDs (3.84 TB for each SSD), and set the RAID policy to RAID 6.
- OceanProtect X8000 file system: Take two SAP HANA servers as an example. Plan two file systems for the two controllers (one for each controller) and 100 TB logical capacity for each file system.
- Logical ports of OceanProtect X8000: OceanProtect X8000 is connected to the two front-end SAP HANA servers through 4 x 10GE physical links. Each physical port is configured with one logical port.
- Storage pool planning:
- On OceanProtect X8000, create two file systems that are owned by controller 0A and controller 0B respectively.
- Mount one file system to each backup media server.
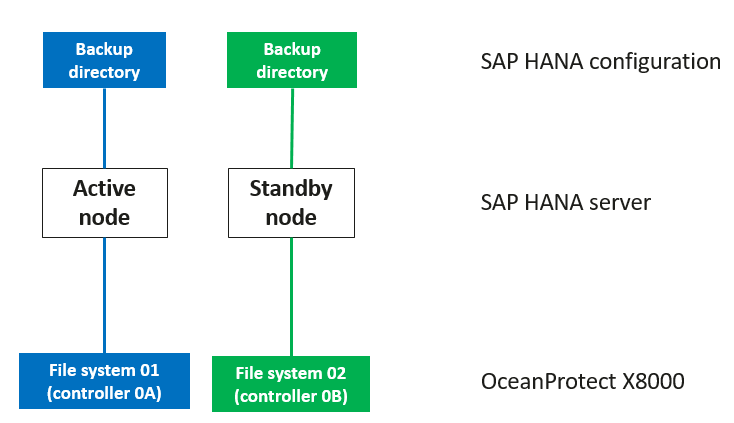
Backup principle: Periodic backup copy data of the same type of applications is written to the same deduplication domain.
Networking principles:
- It is recommended that one backup directory correspond to one file system and one backup directory correspond to one backup media server node.
- To maximize the performance of X9000 HDD, 16 file systems are required.
5.4 SAP HANA Backup and Restoration Configuration
5.4.1 Configuration Process
Figure5-2 Solution configuration process
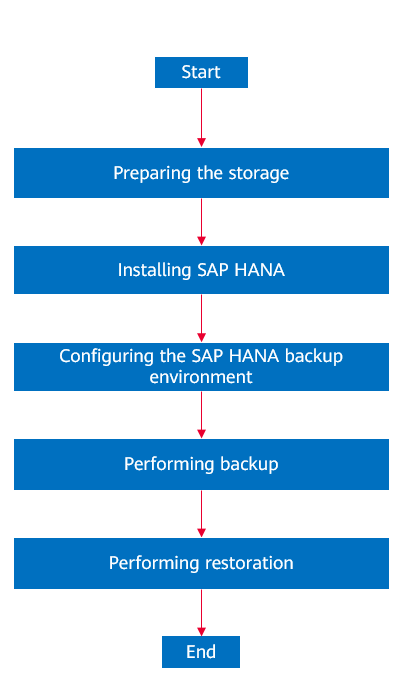
5.4.2 Preparing the Storage
According to planning in this solution, create two file systems and a DataTurbo share on OceanProtect X8000. The configuration procedure is as follows: Create a storage pool, create logical ports, create a file system, and create a share.
5.4.2.1 Creating a Storage Pool on OceanProtect X8000
Step 1 On OceanProtect X8000, select 25 disks to create a storage pool and set RAID Policy to RAID 6.
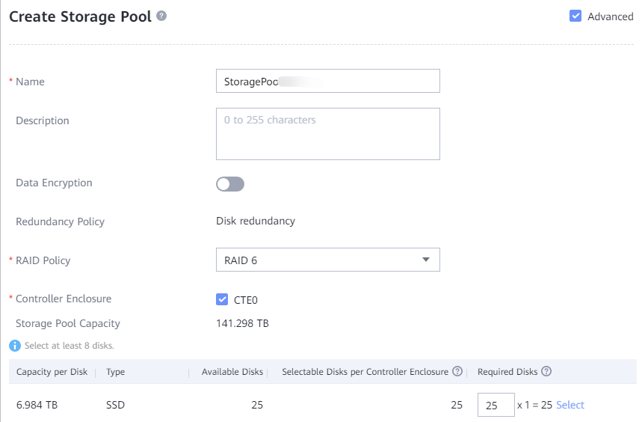
Step 2 Click Advanced, and set Compression Mode, which can be set to High reduction ratio (default) or High performance.

—-End
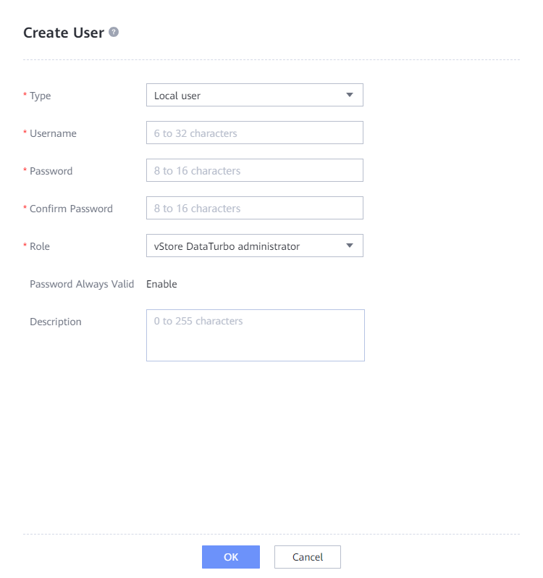
5.4.2.2 Creating a vStore DataTurbo Administrator
Step 1 Choose Services > vStore Service > vStores > System_vStore > User Management, and click Create. Set Role to vStore DataTurbo administrator, enter the username in the Username field, enter the password in Password and Confirm Password fields, and click OK.
—-End
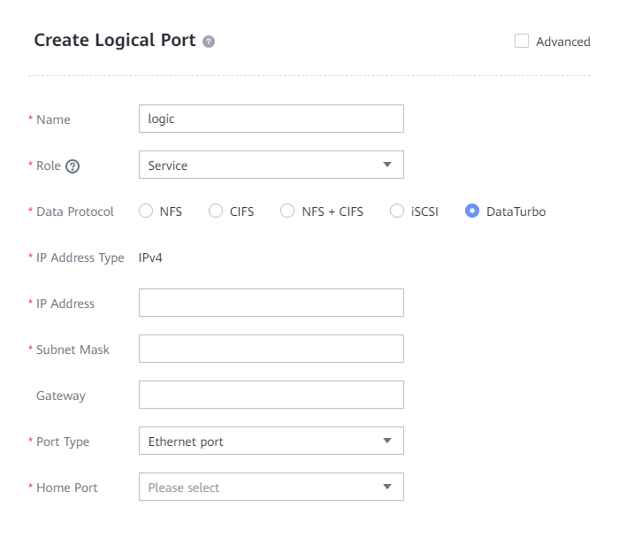
5.4.2.3 Creating a Logical Port on OceanProtect X8000 (TCP Networking)
This step is required when a DataTurbo over TCP networking is used, and is not required when a Fibre Channel networking is used.
In this best practice, OceanProtect X8000 has four physical ports, with each physical port configured with a logical port. Therefore, create a total of four logical ports and set Data Protocol to DataTurbo.
The following figure shows a logical port configuration example.
5.4.2.4 Creating a File System and Share
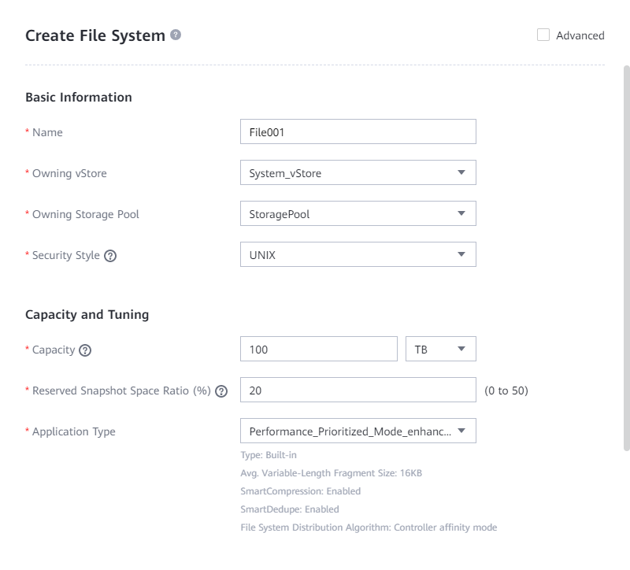
Step 1 Create two file systems (100 TB each) and select the created storage pool.
Step 2 If Application Type is set to Reduction_Prioritized_Mode_enhanced, the high reduction ratio mode is used for the compression mode to save storage resources. If Application Type is set to Performance_Prioritized_Mode_enhanced, the high performance mode is used for the compression mode.
The following figure shows a file system configuration example.
Step 3 Choose Services > File Service > Shares > DataTurbo Shares > Create. Select the file system for which you want to create a share, click Add, and select the vStore DataTurbo administrator created in Step 1.
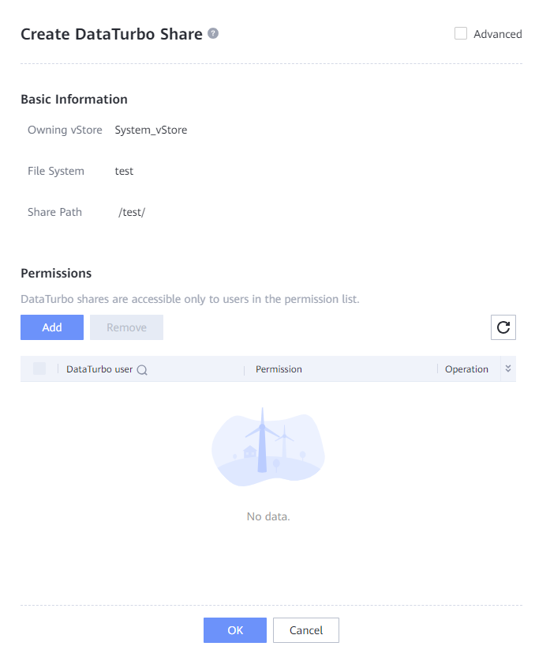
—-End
5.4.3 Installing SAP HANA
This backup solution uses the SAP HANA 2.0 software. For details about how to install the SAP HANA software, see the SAP HANA official documentation.
5.4.4 Configuring the SAP HANA Backup Environment
5.4..4.1 Using DataTurbo to Mount a File System
To mount the planned file system, perform the following steps on active/standby SAP HANA servers separately:
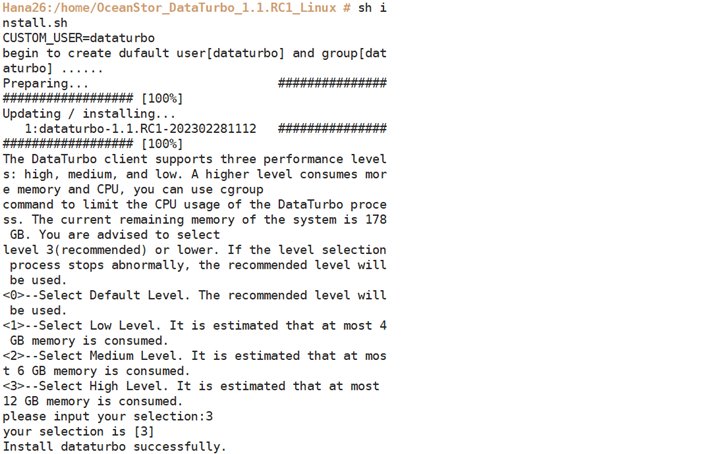
Step 1 On the SAP HANA server, install the DataTurbo plug-in and select a level as required. In this example, select 3, which indicates a high level.
Step 2 Use DataTurbo to create a storage object. Set a user-defined storage_name and set ip_list as the logical port created in the preceding section. Use commas (,) to separate multiple IP addresses. Enter the username and password of the created vStore DataTurbo Administrator.
Command format: dataturbo create storage_object storage_name=? [link_type=IP or FC|ip_list=?]

Step 3 Use DataTurbo to mount the file system by using the storage name, file system name, and mount directory. Create two directories in the mount directory to store SAP HANA data files and log files.
Command format: dataturbo mount storage_object storage_name=? filesystem_name=? mount_dir=?

Step 4 Grant the user or user group to which the SAP HANA service belongs the permission to use the two directories created in Step 3.
In this example, the permission is granted to all users in the operating system.

—-End
5.4.4.2 Configuring the SAP HANA Backup Directory
Step 1 Log in to the SAP HANA studio and connect to the target SAP HANA system.
Step 2 Right-click the tenant database and choose Open Backup Console. In this example, the tenant database is S00.
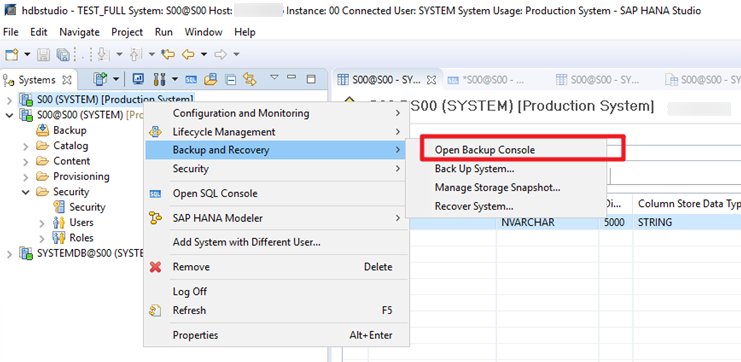
Step 3 Change the SAP HANA backup directories. Change the backup destinations of data files and log files to the directories created in the previous section.
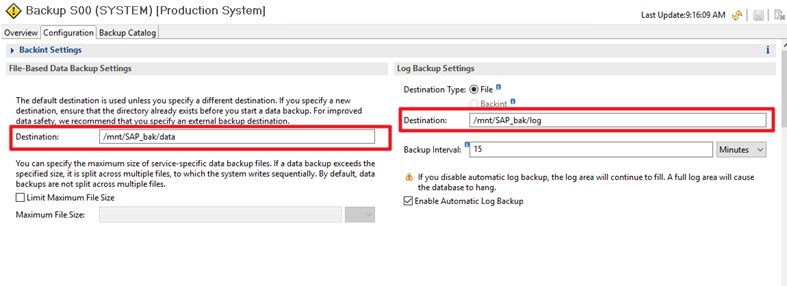
—-End
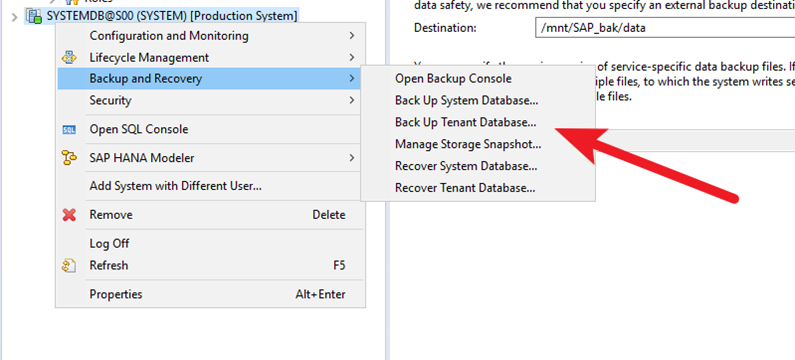
5.4.5 Performing Backup
Step 1 To back up the target tenant database by using the system database, choose Backup and Recovery and click Back Up Tenant Database…..
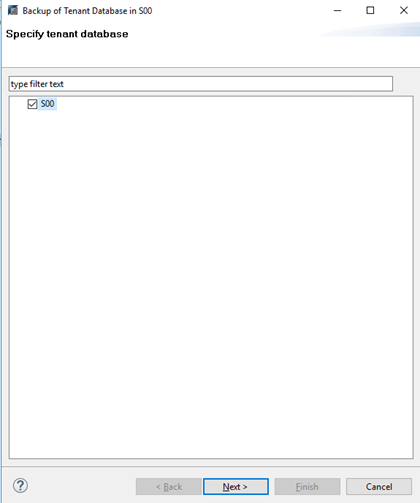
Step 2 Select the tenant database to be backed up.
Step 3 Confirm Backup Type, Backup Destination, and Backup Prefix and then initiate the backup.
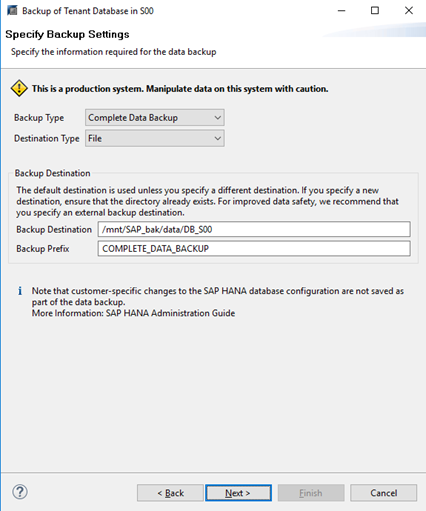
—-End
5.4.6 Performing Restoration
Step 1 To restore the target tenant database by using the system database, choose Backup and Recovery and click Recover Tenant Database.
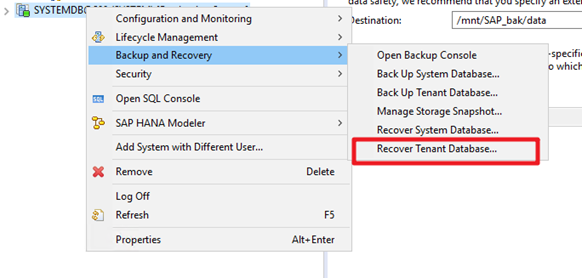
Step 2 Select the tenant database to be restored.
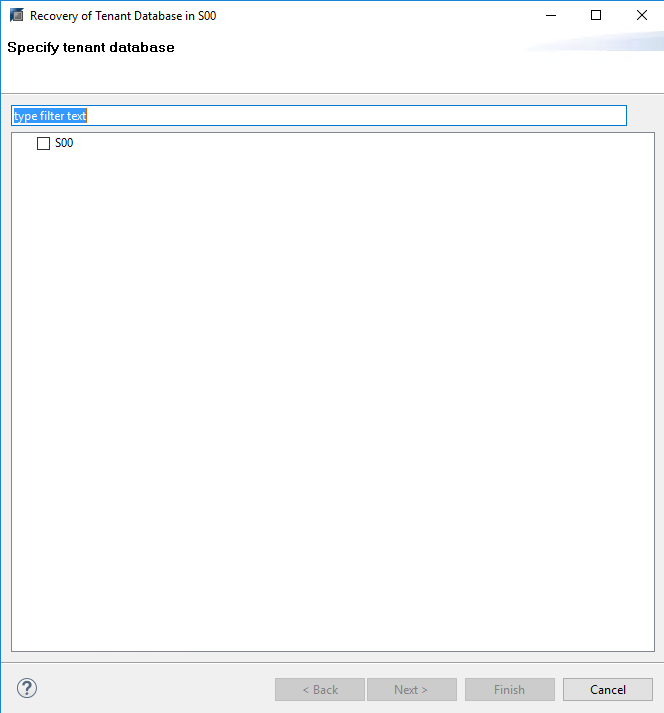
Step 3 Select the required restoration option. In this example, Recover the database to its most recent state is chosen.
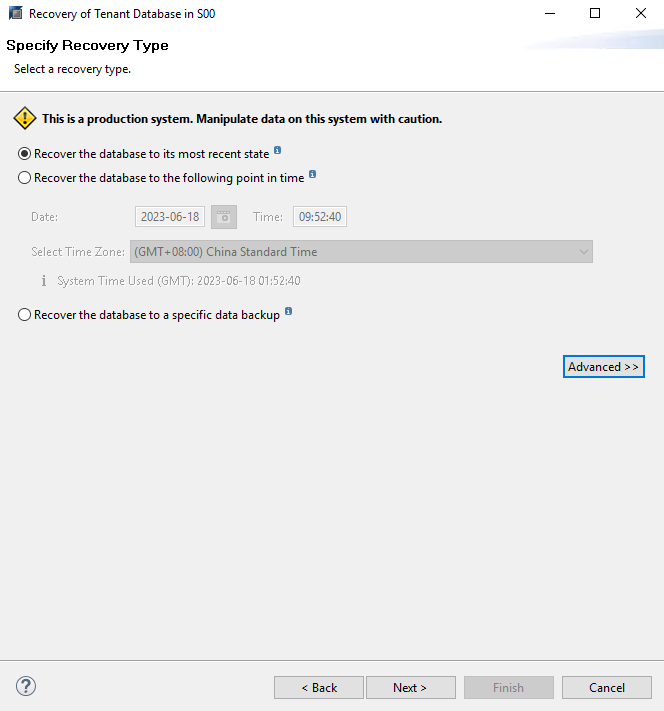
Step 4 Select the copy to be used for restoration and check its availability.
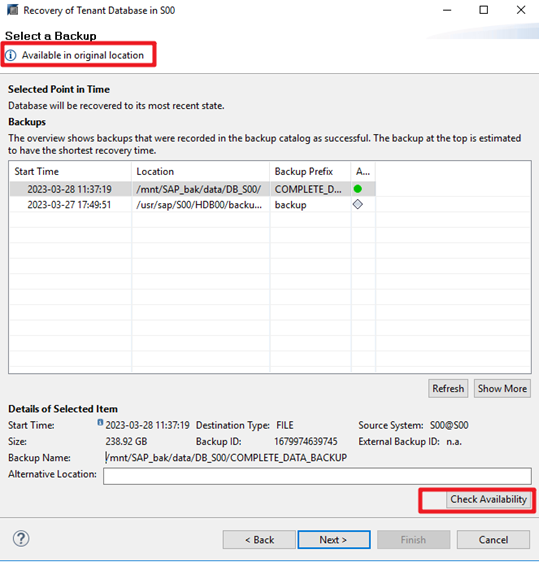
Step 5 Check log backups, whose Locations are the configured backup destination of the log files.
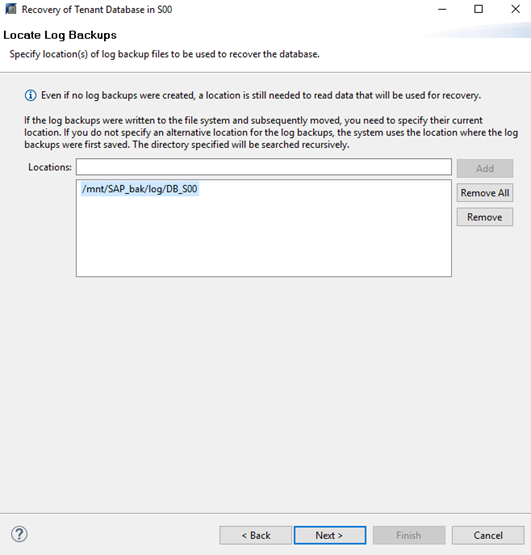
Step 6 Set other restoration options and select File System. If an incremental or differential backup copy is used for restoration, Use Delta Backups (Recommended) must be selected.
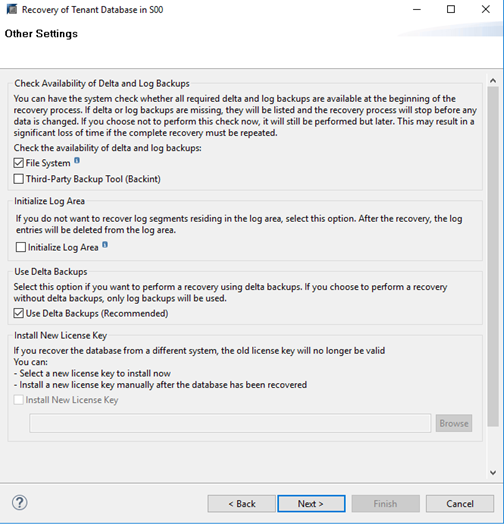
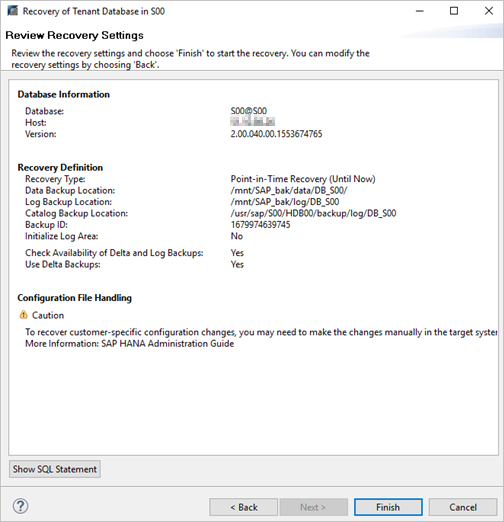
Step 7 This page is the summary page. Click Finish to start the restoration.
5.5 Best Practice Verification Examples
5.5.1 Backup Performance
This solution uses servers (CPU: Intel(R) Corporation Montage Jintide(R) C5218R, memory: 256 GB) to test the backup performance of the active/standby SAP HANA node cluster. The test conclusions are as follows:
The detailed performance test scenarios are as follows:
- Production environment: Two SAP HANA hosts form an active/standby node cluster. In the tenant database, 40 data tables are preset with each data table occupying about 4.9 GB disk space, and the size of the entire tenant database is 239.92 GB. When the cluster status is normal, only the active node runs the backup process.
- Backup environment: OceanProtect X8000 (all-flash) is deployed. Create two file systems on the OceanProtect X8000 and connect them to two SAP HANA servers through DataTurbo over TCP networking.
- Test model: Test the first, second and third full backups. Table 5-3 lists bandwidth performance results.
Backup bandwidth performance test results
Compression Mode | Backup Type | Backup Data Volume (GB) | Backup Duration (s) | Average Backup Bandwidth (GB/s) |
|---|---|---|---|---|
High reduction ratio mode | First backup | 238.92 | 125 | 1.91 |
Second backup | 238.92 | 76 | 3.14 | |
Third backup | 238.92 | 72 | 3.32 | |
High performance mode | First backup | 238.92 | 108 | 2.21 |
Second backup | 238.92 | 79 | 3.02 | |
Third backup | 238.92 | 79 | 3.02 |
5.5.2 Restoration performance
Table 5-4 lists restoration performance test results.
Table 5-4 Restoration bandwidth performance test results
Compression Mode | Restored Data Volume (GB) | Restoration Duration (min) | Restoration Bandwidth (GB/s) |
|---|---|---|---|
High performance mode | 238.92 | 4 | 1.12 |
High reduction ratio mode | 238.92 | 4 | 1.06 |